

Duplicate records are a challenge that all Salesforce Admins face. I’ve seen duplicates in every single Salesforce org I’ve ever worked in (even the ones that assured me there were no duplicates!). The problem is made worse with the misconception that Salesforce blocks and manages duplicates out-of-the-box. That isn’t true, and the situation is made harder because every organization defines “duplicate” differently.
Fighting duplicate records in Salesforce is a battle on two fronts: Prevention and Cure. There are multiple ways you can prevent Salesforce duplicates (including standard and paid options) – but if you find that you’re too late to put these essential guardrails in place, there are ways to clean up duplicate records too.
Duplicate Rules vs. Matching Rules
Throughout this post, I will refer to both Duplicate Rules and Matching Rules – here are the differences between them:
- Matching Rules: Will identify what field and how to match. For example, “Email Field, Exact Match” or “Account Name, Fuzzy Match”. Matching rules, alone, don’t do anything. Compare this to a recipe without a chef.
- Duplicate Rules: Will use those matching rules to control when and where to find duplicates. For example, “Use Account Name, Fuzzy Match” to find duplicates on the Account object upon creation or “Use Email, Exact Match” to find duplicates on Leads and Contacts, upon create and edit. Compare this to a chef with the recipe (i.e. the matching rule).
Duplicate rules can trigger two possible outcomes:
- Alerting the user creating a duplicate.
- Blocking the creation of a duplicate record.
Salesforce Standard Duplicate Rules
Out-of-the-box, Salesforce provides three matching rules for Accounts, Contacts, and Leads. These alone are insufficient because:
- These rules don’t cover every scenario.
- The error messages are not helpful to your users.
How Can You Extend Deduplication in Your Salesforce Org?
- Create your own Salesforce Duplicate Rules: Salesforce allows you to create your own. Despite limitations to how far you can take duplication rules, you may find that these are sufficient without spending extra budget to prevent duplicates going forward.
- Invest in a third-party app to prevent dupes (and find a deduplication service for your existing records, depending on the size of your org and your capacity.
But first, let’s find out how you can identify duplicate records in Salesforce…
How to Identify Duplicates in Salesforce
Duplicate Jobs (covered later in the guide) are designed for this purpose, however, they are only included in the higher editions of Salesforce – so, not a viable option for everyone.
For quick, free ways to check the extent of duplicate rules in your Salesforce database, you can create a Salesforce report and use the “Show Unique Count” function.
To take this a step further, create a custom report type using the “Duplicate Records Items” object in the object relationship.
Prevention: Create Your Own Salesforce Duplicate Rules
These are the six Salesforce duplicate rules you need to activate – right now. Creating these rules will help you get to grips with how Salesforce duplicate rules work, before potentially graduating to a more advanced option from the AppExchange.
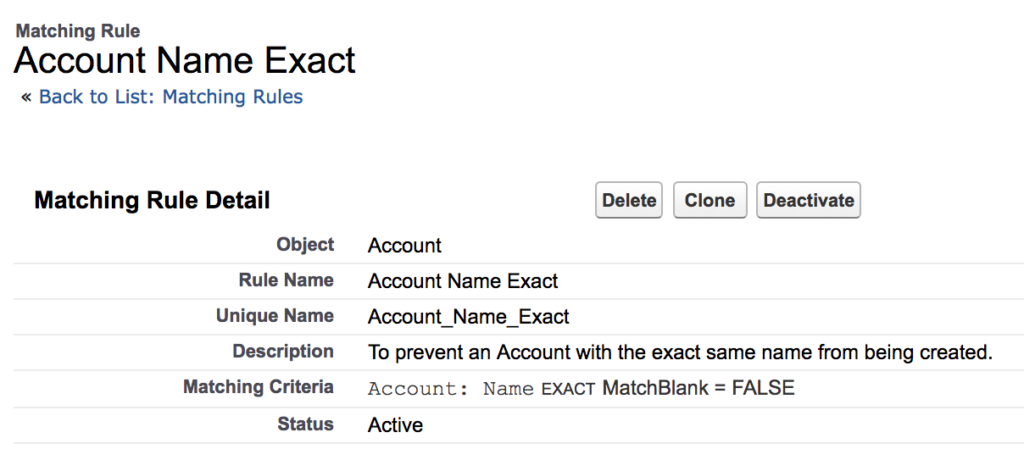
1. Account Exact Name Rule
Let’s start with Accounts. When users create Accounts, they are probably in a hurry (well, they’re always in a hurry!). But no matter how much training you provide, the chances are that they aren’t going to search for this company to see if it already exists. So, we can assume our users are going to create duplicates.
Purpose: Prevent multiple Accounts with the exact same name from being created.
- Create an “Account Exact Name Matching Rule”.
- Then, create an “Account Exact Name Duplicate Rule”:
- Use the matching rule you just created, and give it a unique error message.
- Make sure you select “Block” on both Create and Edit Actions.

2. Account Name Fuzzy Match
This is when you would want to flag a potential duplicate to users, but not block what could genuinely be a separate account, for example:
- Companies that use an acronym. A user that types “Inc.” instead of “Incorporated”.
- Different branches of the same company, with a very similar naming convention (common for international companies “Tech Company North America” and “Tech Company UK”.
Here we will use Salesforce’s Fuzzy logic.
Purpose: Warn users of a potential duplicate where account names differ slightly.
- Create an “Account Name Potential Match Matching Rule”.
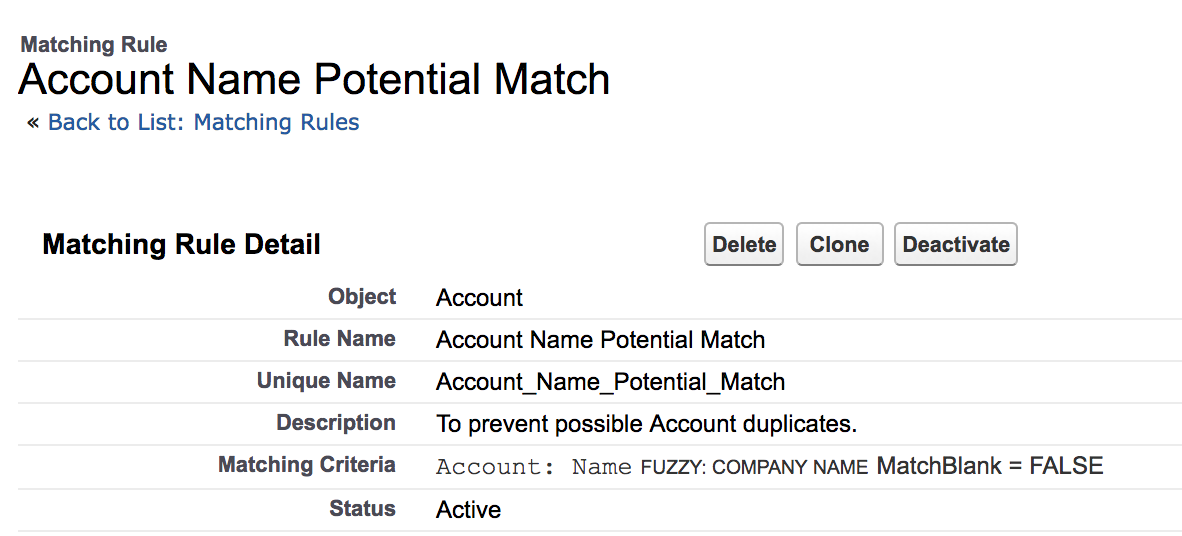
- Then, create an “Account Name Potential Match Duplicate Rule” and be sure to Allow on “Create and Edit Actions”.

Leads & Contacts (“People” Duplicates)
Leads and Contacts are a bit more complicated. Sometimes users will say “I want to prevent Lead duplicates” or “I want to prevent Contact duplicates”. Both are great goals, but this still does not solve the total duplicate problem – even in tandem.
Leads and Contacts boil down to one thing: individual people. Not only do we need to prevent Leads duplicates and Contacts duplicates, but we also need to prevent users from creating Contacts that are already Leads, and prevent users from creating Leads that are already Contacts.
There are four scenarios within this that we need to prevent:
- New Leads that already exist as Leads
- New Leads that already exist as Contacts
- New Contacts that already exist as Contacts
- New Contacts that already exist as Leads
I prefer to manage these each as their own individual duplicate rule so that I can give each one a very specific error message, and tell the user what they need to do to resolve it. I also only base my rules on a person’s email address. It’s perfectly normal for two or more people to have the exact same first and last name, so I do not create any rules (even fuzzy) based on first and last name.
Create a “Lead Email Exact Matching Rule”, as shown below:

Then, create a “Contact Email Exact Matching Rule”, as shown below:

We’re going to use these two matching rules to make the rest of our duplicate rules…
3. Lead-to-Lead Email Exact Match
Purpose: To prevent the creation of multiple Leads with the exact same email.
The Lead-to-Lead Email Exact Match Duplicate Rules will look like this:

4. Lead-to-Contact Email Exact Duplicate Rule
Purpose: Prevent the creation of multiple Leads-to-Contacts with the exact same email.
Ensure you compare Leads to Contacts, and give it a unique error message:

5. Contact-to-Contact Email Exact Duplicate Rule
Purpose: To prevent the creation of multiple Contacts with the exact same email.
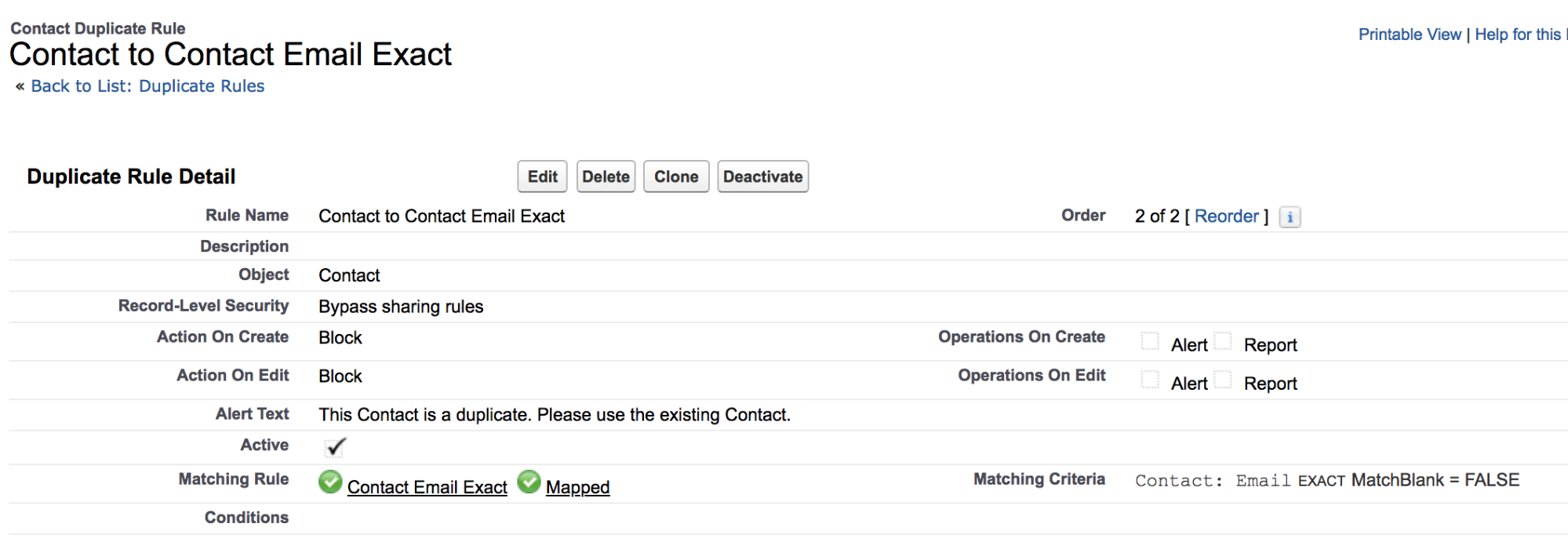
6. Contact-to-Lead Email Exact Duplicate Rule
Purpose: Prevent the creation of multiple Contacts-to-Leads with the exact same email.
Create a “Contact-to-Lead Email Exact Duplicate Rule”:

Make sure you compare Contacts to Leads, and give it a unique error message.
Deduplicating your Salesforce Org Data: 5-Phase Process
Our friends over at Plauti (the people behind Deduplicate) outline a 5-phase process:
- Data Requirements: List all objects that need deduplicating, the relevant fields for each object, indicate matching method for all fields, and the words to ignore.
- Process Requirements: Answer questions to find what you need.
- Tool Selection.
- Implementation: Start configuring your matching rules with the tool of your choice. Look at the results but do not automate anything yet.
- Maintenance: Scheduled cleanups are essential to keeping your Salesforce squeaky clean – but ‘set and forget’ is not the way to go.
You’ll find a more detailed walkthrough in the guide below:
Cure: Merge Records in Salesforce
Salesforce users (or admins needing a quick fix for a few records) can manually merge selected records, selecting the “source of truth”, by field.
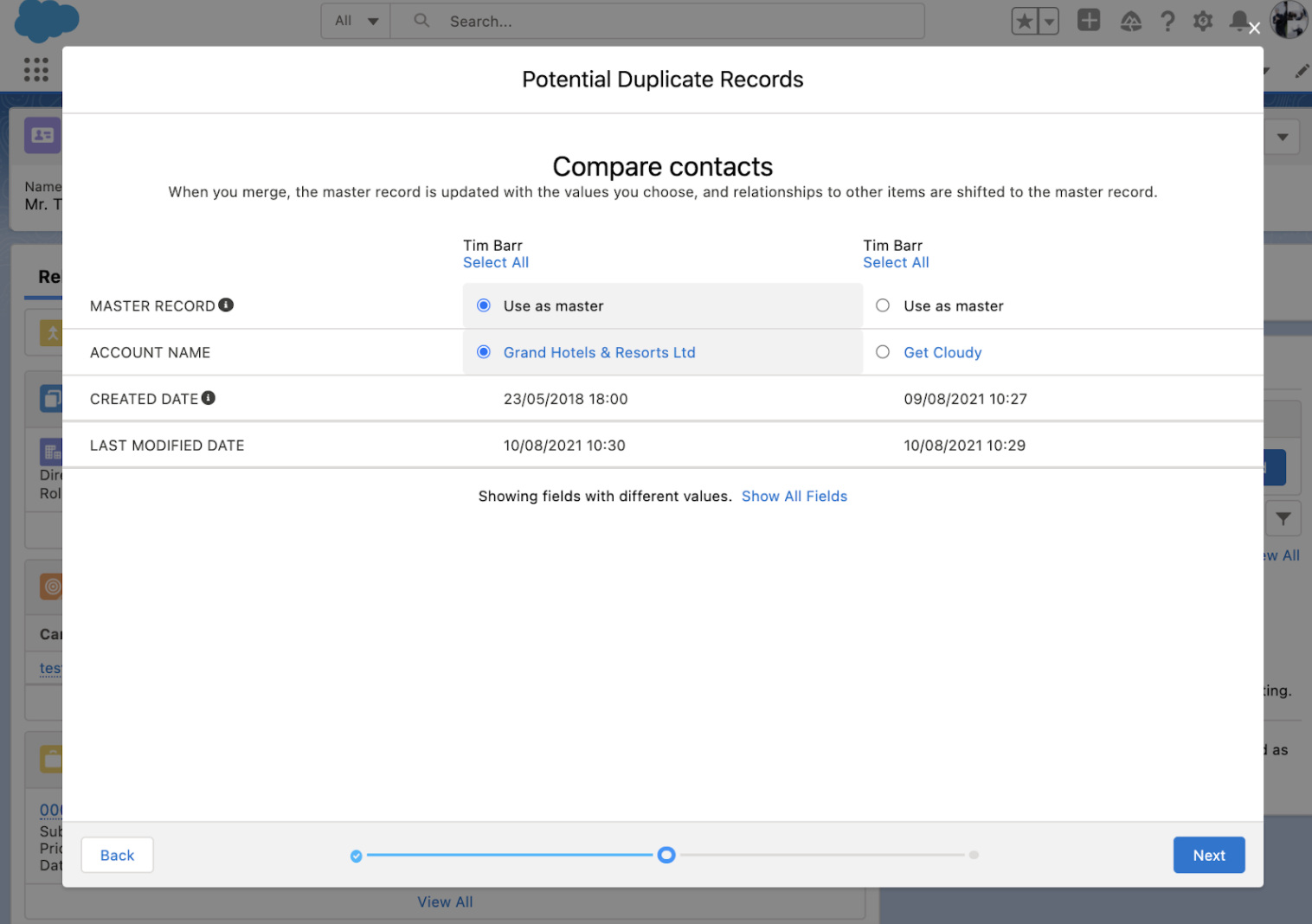
Cure: Salesforce Duplicate Jobs
Duplicate Jobs scan your Salesforce database for duplicates, and allow you to action using “Compare and Merge”. This is only available in Salesforce Performance and Unlimited editions, so if Duplicate Jobs are missing in Salesforce, it’s because you are on a lower tier edition of Salesforce.
Prevent and Cure: Extending Salesforce Deduplication
The Salesforce partner ecosystem exists because of the innovation they bring to plug Salesforce gaps. By investing in a third-party app, you may find that even the gnarliest deduplication tasks get sorted. With feature-rich apps, you’re likely to find more than you’d initially expected!
Two of the tools available are:
You can also deduplicate by using machine learning algorithms. These are trained to dedupe not only Salesforce, but any unstructured data. More information available in the article below:
Summary
In this guide, we’ve explored Salesforce Duplicate Rules and beyond! We’ve gone into how you can identify the need to use them, as well as how to leverage third-party apps in your mission for clean data.
Here’s a refresher of the key terms:
- Duplicate Rules: Use matching rules to control when and where to find duplicates.
- Matching Rules: Identify what field and how to match. For example, “Email Field, Exact Match” or “Account Name, Fuzzy Match”.
- Standard Duplicate Rules: The out-of-the-box matching rules that Salesforce provides for Accounts, Contacts, and Leads.
- Custom Duplicate Rules: Duplicate rules created by building custom solutions.
- Exact Match: Names that are the exact same.
- Fuzzy Match: A potential duplicate that could also genuinely be a separate account.
- Duplicate Jobs: Scan your Salesforce database for duplicates, and allow you to action using “Compare and Merge”.
The definition of what a “duplicate” is differs by organization, and then, by Salesforce object. That’s why deduplication takes careful planning and continuous monitoring. Start with the 5-phase process for deduplicating your Salesforce org data and go from there. Good luck!

Comments: