





Salesforce Ben has published numerous posts about how duplicate records are an issue in Salesforce. They kill the productivity of marketing and sales teams, increase costs, and ruin customer experience.
Almost all solutions to find duplicates rely on different matching methods to identify duplicate records. Finding duplicates involves comparing and evaluating a set of field values on a ‘record A’ and a ‘record B’. This matching involves two steps: first, the comparison and evaluation of specific fields, and second, combining the scores of the selected fields for an evaluation of the records themselves. If the second one meets the threshold, the records are presented as duplicates.
In this blog, we will explore the most important matching methods and when to use them, followed by some best practices in combining matching methods in a matching rule or scenario. Since all matching methods can be divided into two main groups: exact and fuzzy matching, that is where we’ll start.
Tip: note that different vendors use different names for the same thing (matching method and matching algorithm are the same)
Matching Methods
Exact Match
For an exact match method to evaluate two fields as duplicate they have to match…exactly. So, a match is either true or false.
Example:
| Record A | Record B | Method | Evaluation |
|---|---|---|---|
| John Doe | John Doe | Exact | true |
| Jon Doe | Jon Doe | Exact | false |
Some solutions offer variations on exact match, such as ‘Exact (Random Order)’:
| Record A | Record B | Method | Evaluation |
|---|---|---|---|
| John Doe | Doe John | Exact (Random Order) | true |
As you can see “Exact (Random Order)” means the individual words have to match exactly, but not necessarily in the same order.
Fuzzy Match
Fuzzy matching will return a match when two fields are alike (similar). It’s like looking through almost closed eyelids, with your vision becoming fuzzy and it’s hard to distinguish small differences between words.
Similarity, scoring often involves a combination of different algorithms. One of the most used algorithms is based on the concept of ‘Edit distance’. This is sometimes also called ‘Levenshtein distance’ after the Soviet mathematician Vladimir Levenshtein, who did extensive research on the subject.
Edit distance is the number of single character edits (insert, delete or change) needed to change one string into another.
Jon Doe <> John Doe has an edit distance of 1. In this case only the insertion of the letter ‘h’ in John will make the two strings equal.
The goal of matching is to return similar results (with the same meaning). Purely using edit distance for this goal is not ideal, especially for shorter strings (names, words). Consider the following:
| Record A | Record B | Method | Edit Distance | Intended Meaning |
|---|---|---|---|---|
| Cat | Hat | Fuzzy | 1 | Very different |
| Elephant | Elephont | Fuzzy | 1 | Same |
Shorter strings often have entirely different meanings with one or two edits. The longer the string, the less the impact of an edit on the meaning. To combat this problem, most deduplication solutions use a matching score based on multiple fields and a threshold to determine duplicate records.
Matching score is generally calculated by subtracting the result of the division of the found edit distance by the maximum edit distance of the two values of 1. The process to calculate the maximum edit distance is too complex to show here. However, it is based on the length of the longest string.
| Record A | Record B | Method | Edit Distance | Max. Edit Distance | Score |
|---|---|---|---|---|---|
| Cat | Hat | Fuzzy | 1 | 3 | 66,6% |
| Elephant | Elephont | Fuzzy | 1 | 8 | 87,5% |
As you can see, the score is much higher for longer strings with the same edit distance. Setting a high threshold when using fuzzy matching makes sure you don’t get too many false positives.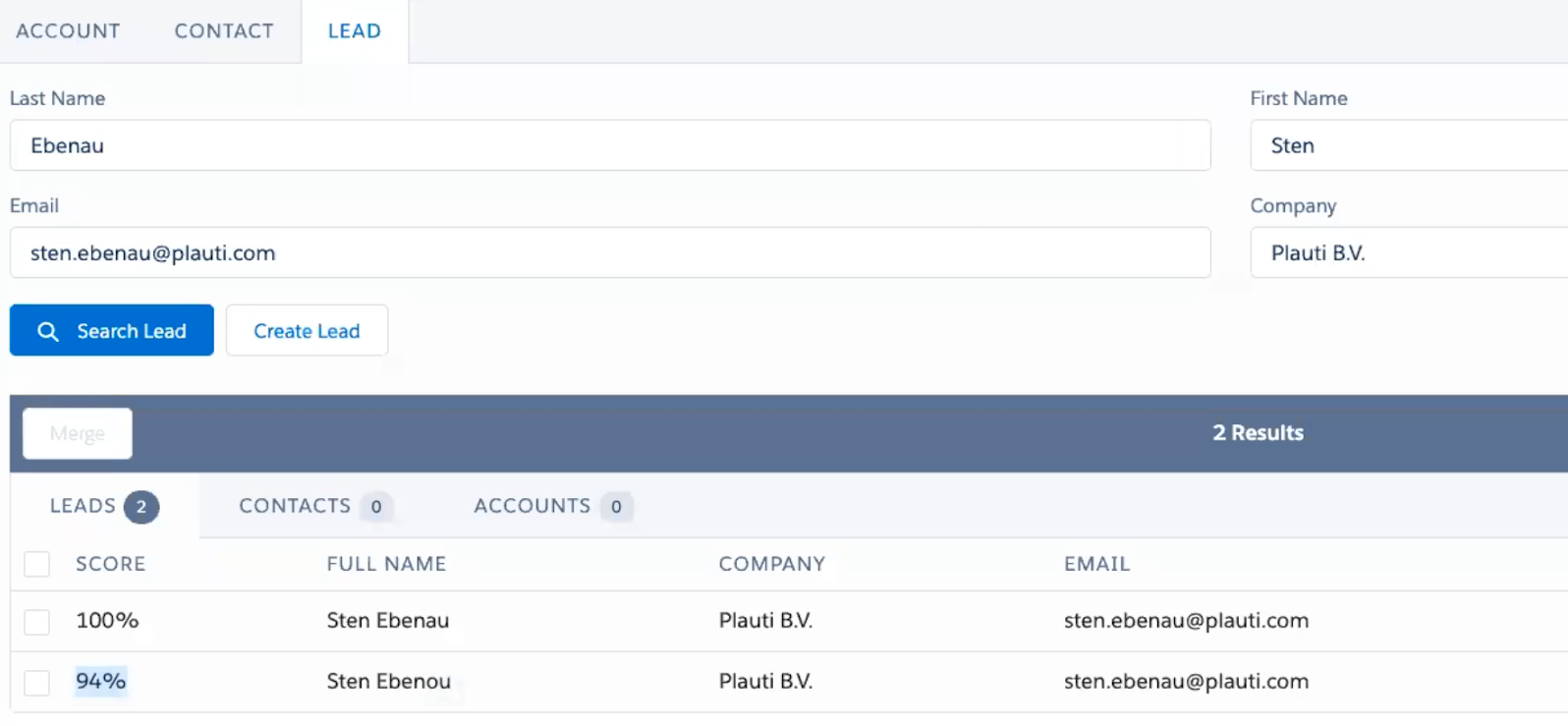
Note: A different letter in the last name leads to a lower score.
Special matching methods
Almost all deduplication solutions offer more specialized matching methods. Most of them are based on either exact or fuzzy and include some additional logic. When matching telephone numbers, you will get much better results if they are in the same format. A specialized phone number matching method will ignore spaces, dashes and standardize prefixes for a valid comparison. A matching method specific for company names may ignore legal entities (such as Inc., Ltd., LLC, etcetera). My advice is to always apply a special matching method, when it is available for a field you want to include in your matching. These matching methods will give you fewer false positives when looking for duplicates.
Best practices in scenario building
Based on our years of experience building Duplicate Check and consulting clients we share some best practices with you.
A scenario consists of a number of fields with corresponding matching methods and aims to find duplicates for a specific Object. You include fields that are (almost) unique for a single person, such as first name, last name, phone number, email address, birth date, social security number and so on.
Example of a scenario to find duplicates in the Lead object:
| Field | Method |
|---|---|
| First Name | Fuzzy (Names) |
| Last Name | Fuzzy (Names) |
| Company | Fuzzy |
| Email Address | Fuzzy (Email) |
How to treat empty fields
In a scenario, you combine different matching methods on different fields to evaluate if records are duplicate. In a lot of cases, you are comparing an empty field with a field containing a value. You can treat an empty field in three different ways:
A. Score 0% match
B. Score X%
C. Ignore
How to treat empty fields depends on the fill rate of the field you have included in your scenario. My advice would be to use a 0% match (no match) if you have a high fill rate. If your fill rate is low, go for ‘ignore’ or ‘score 50%’.
If you go for a combine scenario approach, as outlined in the next paragraph, definitely go for ‘score 0%’. Since a scenario typically relies on 3 or 4 fields being combined for an evaluation, ignoring the field will lead to a scenario using 2 or 3 fields. This is too few and will lead to many false positives.
Combine scenarios
Do not build scenarios containing lots of fields! Go for an approach of using 3 or 4 fields for a scenario and using multiple scenarios for the same Object to find all duplicates instead.
For example:
First Name AND Last Name AND Email Address >90%
OR
First Name AND Last Name AND Phone Number >90%
OR
First Name AND Last Name AND Company Name >90%
In the example above we use three different scenarios to find all duplicates in the Lead object. As you can see, it is best practice to keep the name fields across all scenarios and switch a second identifying field.
Match Across Fields
A lot of organizations store similar information across multiple fields. Take the field ‘Email’ and ‘Secondary Email’. Obviously, you want to match john.doe@example.com, regardless if it is stored on ‘Email’ in Record A and on ‘Secondary Email’ in Record B.
Different deduplication solutions offer different ways to solve this. Have a look in the knowledge base or contact support to confirm if your preferred solution offers this option.
Ignore words
This one is especially useful if you are targeting organizations within a specific niche (that is included in the organization’s name). Let’s assume you are targeting libraries and are evaluating the following two Accounts using a fuzzy matching method:
Account Name
Municipal Library of New York
Municipal Library of New Jersey
Since a large part of the string is similar, the resulting score will be very high. Unfortunately, the whole ‘Municipal Library’ part does not tell us anything (remember, we are only targeting libraries here). Most solutions offer a feature to ignore specific words or strings. I suggest you use this when you have a similar use case. In this case it would be wise to put ‘municipal library’ on the ignore list.
Note: Prevent records like these showing up as duplicates by ignoring words.
Summary
Good luck finding all duplicates in your Salesforce org! Duplicate Management solutions can be very powerful, so do not hesitate to contact your vendor, if you struggle to build good scenarios to ensure you get the most out of the functionality on offer.




Comments: