

I often see Salesforce teams run into the same issue. Duplicate records and other data quality issues start small but, over time, they begin to affect reporting, customer histories, and pipeline visibility.
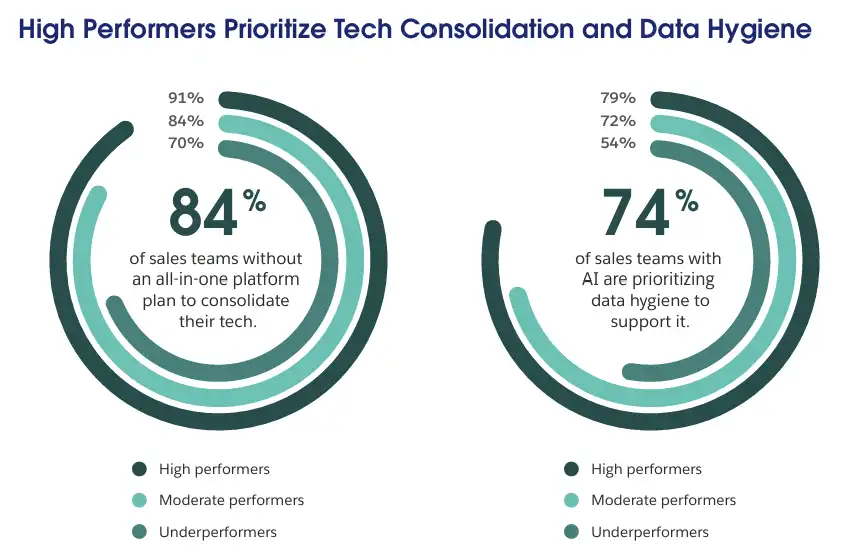
This is why data quality becomes a priority for top-performing teams. According to Salesforce’s State of Sales report, 79% of high-performing sales teams using AI prioritize data hygiene to support it. Even the most advanced tools still depend on clean, consistent data.
At the same time, broader conversations about AI kept coming up. Some teams expected that AI would help identify and even resolve duplicates and bad data automatically. It sounds reasonable. If AI can analyze large datasets, why not use it for Salesforce duplicate management?
But when duplicate records impact customer history, sales pipelines, and reporting accuracy, the question becomes more practical. It then becomes about deciding what happens next.
In this article, I want to look at where AI actually fits into Salesforce data deduplication, where its role is limited, and why organizations still rely on controlled, rule-based approaches.
Why AI Is Entering the Deduplication Conversation
It is not hard to see why AI has entered the deduplication discussion. Data volumes continue to grow. According to 2025 Salesforce research, data and analytics leaders estimate their organizations’ data volumes are increasing by around 30% annually, up from 23% in 2023.
Simple matching rules can catch exact matches, but they miss cases where records are slightly different. For example, the same contact might appear with variations in name, email, or company details. Over time, these differences make it harder to rely on a basic duplicate check in Salesforce, especially in large datasets.
That’s when AI often comes to mind. AI is widely used to analyze large datasets, which leads to a reasonable question: Can the same approach be applied to deduplication?
Does Deduplication Really Require AI?
AI can help identify patterns and suggest possible duplicates across large datasets. In some cases, AI can also assign confidence scores to potential matches. In complex Salesforce environments, this can be useful, especially when records are not exact matches.
However, identifying duplicates is only part of the process. On its own, AI does not fully address what happens next: how duplicates are handled, how records are merged, and how data remains consistent over time.
Why Reliable Automation Matters More Than AI in Deduplication
When deduplication processes run automatically, they directly impact critical business data, including accounts, contacts, and duplicate cases in Salesforce.
At this stage, the focus shifts from identifying possible duplicates to understanding how they are handled. Deduplication is not only about finding similarities. It is about making decisions around eliminating those duplicates. For example:
- Which record should remain and which should be removed?
- Which field values should be preserved and which should be overwritten?
- How should conflicting data (for example, different emails or account ownership) be resolved?
- Should certain records be excluded from merging based on business rules?
Organizations need predictable, rule-aligned outcomes. AI can highlight potential matches, but it does not always provide clear reasoning for why records should be merged or in what way. This lack of transparency makes fully automated decisions harder to trust.
For this reason, even as AI grows increasingly common, Salesforce teams prefer deduplication systems where the automation logic remains transparent and fully controlled. Matching criteria, merge rules, and outcomes must be clearly pre-defined so the process can be reviewed, adjusted, and trusted over time.
The Tools Behind Reliable Salesforce Deduplication
Salesforce Administrators typically start with native duplicate management features. Salesforce provides Matching Rules and Duplicate Rules, where each duplicate rule in Salesforce defines how records are evaluated and when potential duplicates are flagged.
These features work well when the data is simple, and volumes are manageable. However, as organizations grow, data becomes more complex, and common challenges, such as Salesforce limitations, become more noticeable when managing records at scale.
Native tools primarily help detect and prevent duplicate records in Salesforce, but offer limited support for actually managing duplicate record sets at scale or running ongoing cleanup processes across large datasets.
As complexity grows, organizations adopt specialized Salesforce duplicate management processes. These processes typically:
- Identify and group Salesforce duplicate record sets across large volumes of data
- Run scheduled or automated cleanup jobs
- Apply consistent merge logic across records
- Support ongoing data quality as data grows
Instead of relying on AI-driven decisions, such tools use rule-based logic defined by administrators. Matching criteria, filters, and merge rules are configured explicitly, which allows teams to control how duplicates are identified and, more importantly, how they are resolved.
A Practical Example: Reliable Deduplication With Cloudingo
Cloudingo is one example of this approach. Instead of relying on automated assumptions, it allows administrators to define matching filters that determine how records are grouped into duplicate sets. Filters can be configured across multiple fields using varying matching algorithms and adjusted to the organization’s data structure.
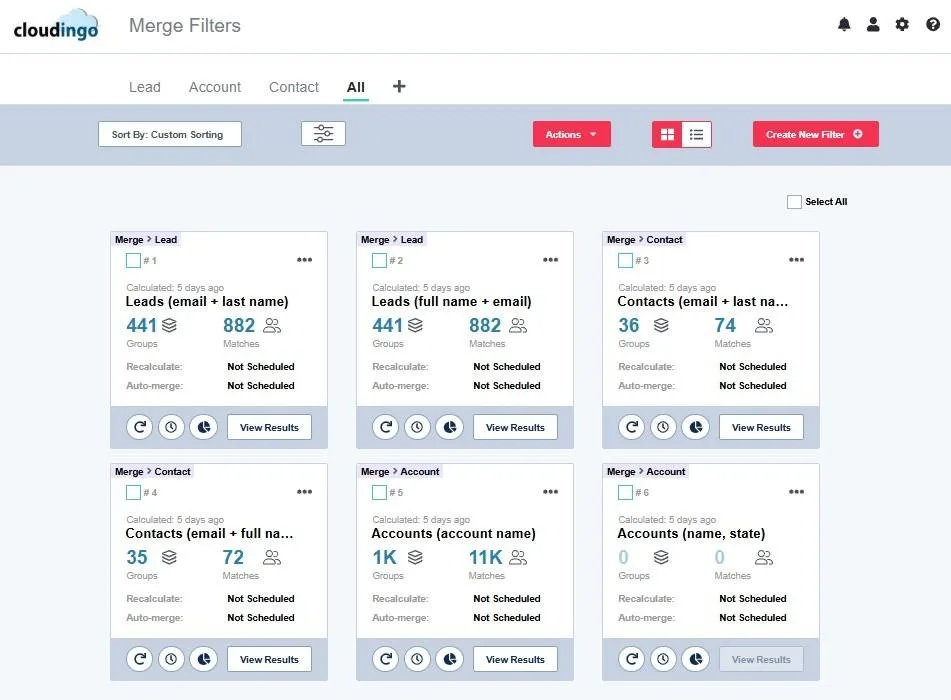
Once duplicate records are identified, administrators can review record sets before taking action. Rather than applying a one-size-fits-all merge, Cloudingo Salesforce deduplication allows teams to apply user-defined, detailed merge rules and retain the option for manual review when needed.
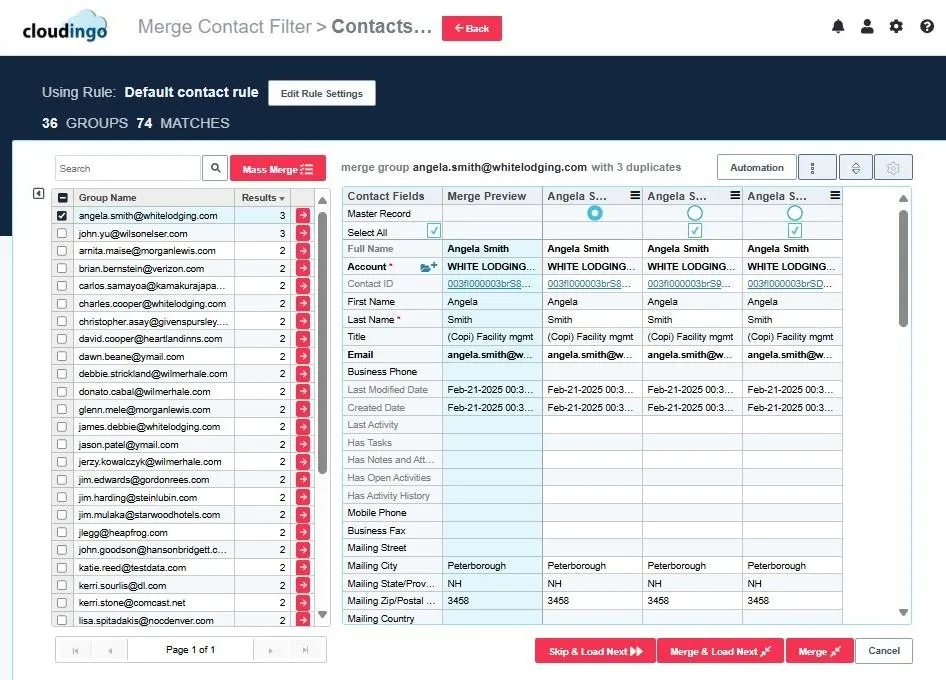
Cloudingo also supports automated cleanup through scheduled jobs.
Throughout this process, visibility remains a key part of the workflow. Administrators can see how records are matched, how merge decisions are applied, and what changes are made to the data. This makes it easier to validate outcomes, adjust rules, and ensure that deduplication aligns with internal data standards.
The Cloudingo approach reflects duplicate management best practices: automation should be controlled, transparent, and aligned with clearly defined rules.
Rather than replacing decision-making like some AI approaches would, tools like Cloudingo support a structured, predictable, and auditable approach.
Final Thoughts: The Role of Reliability in Modern Salesforce Deduplication
AI will continue to influence CRM data management, including Salesforce Data Cloud deduplication. However, deduplication is not only about identifying similar records. It requires decisions that directly affect data integrity and reporting accuracy, and that support operational efficiency and accuracy.
The priority is not simply to detect duplicates, but to ensure that every action leads to a predictable and controlled outcome. For this reason, structured tools and clearly defined automation remain a key part of modern Salesforce deduplication.
A practical first step is to evaluate your current Salesforce data quality. Cloudingo’s free trial gives you access to the Data Quality Dashboard, where you can review duplicate trends and overall data health.
