





The primary goal of developing on the Salesforce platform is to deliver innovations with the fastest velocity possible – yet, something is slowing the process down between development and go-live.
How much time do you spend debugging errors in Salesforce production environments? According to Stripe, the average developer spends more than 17 hours a week debugging…that’s almost half a week spent fixing pushed code rather than developing new features! In fact, upward of $300 billion in global GDP is lost because developers pour time into fixing code.
When bad code is released from coding and testing into production, it takes three times as long, and costs up to fifteen times as much, to fix bugs. In order to avoid corrupting production data and business processes, it all starts with relevant, fresh test data for complete testing. Getting that data into a sandbox, however, can be very difficult and time consuming.
What is Sandbox Seeding?
Before I go into covering the challenges, I’m going to define what sandbox seeding is. In short, sandbox seeding is how you populate sandbox environments with data for testing development work.
To help developers and administrators enhance their org, Salesforce offers four different types of sandboxes: Full Copy, Developer, Developer Pro, and Partial Copy. While all sandboxes provide a repository for development and testing, only Full Copy sandboxes provide an exact replica of complete production metadata and data. Since most development and testing work is done in the other three smaller sandboxes, you need to populate the environments with data. This process is commonly known as sandbox seeding.
4 Sandbox Seeding Challenges
Here are 4 challenges you’re likely to face if you’re not testing with fresh test data in your sandbox.
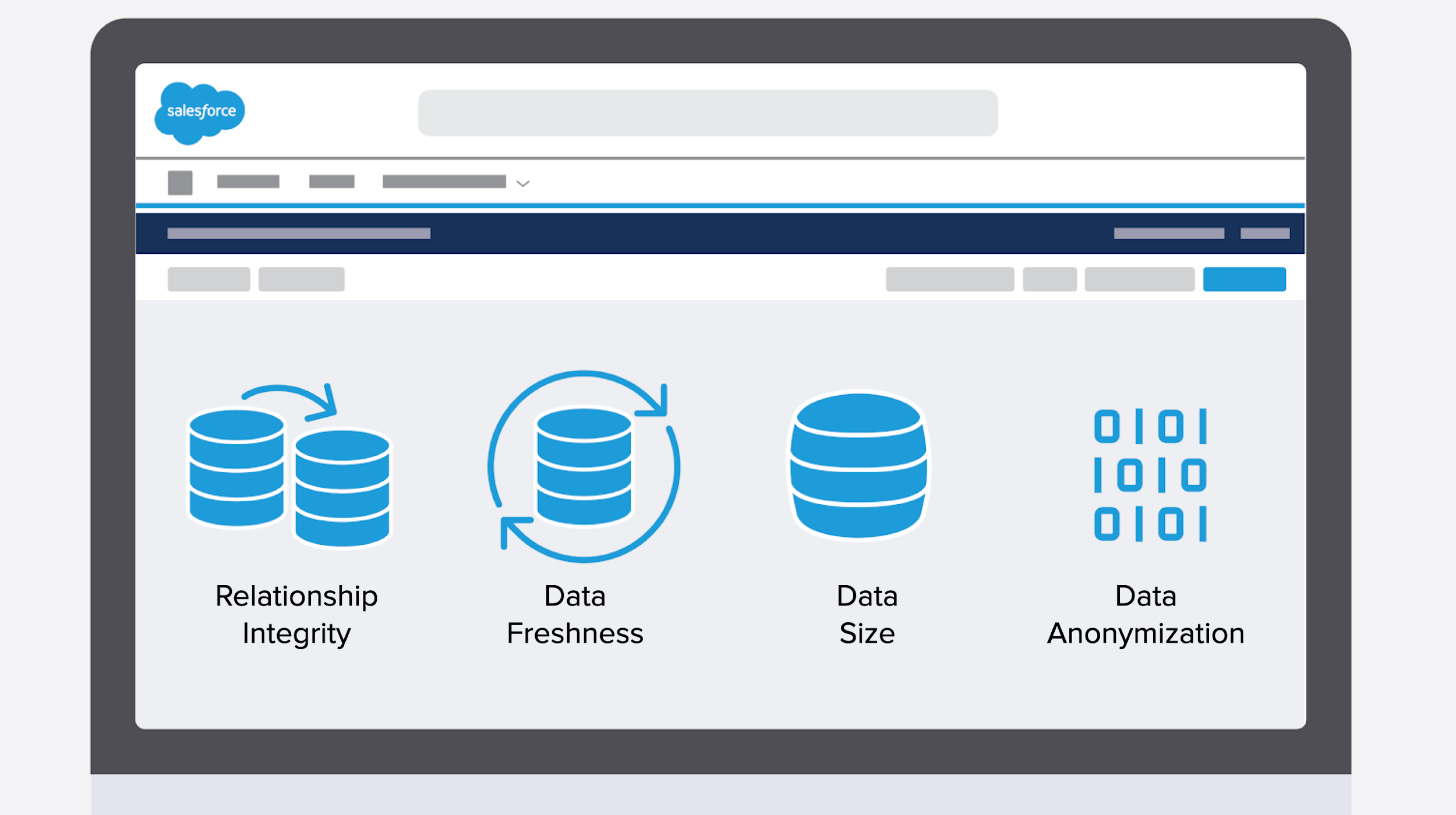
1. Data Relationship Integrity
Accurate development and testing hinges on seeding sandboxes with production-like datasets. The most difficult barrier is maintaining parent/child relationships.
Similar to recovering lost data with the Weekly Export .CSV files, maintaining data relationships when seeding sandboxes can be challenging with Excel and Data Loader. Both require multiple steps.
2. Data Relevancy
You cannot fully test when limited to irrelevant data. Seeding your sandboxes, or moving relevant, sized-to-fit test data into a sandbox, can be like using a funnel to filter sand from a dump truck. You end up buried in tons of irrelevant data. Testing with irrelevant data causes bugs and errors to slip into production, even if you thought you had fully tested in your sandbox.
The reason it is so difficult for many developers and admins to get relevant, sized-to-fit data is that they’re testing in smaller sandboxes that can only fit part of the data from production. To seed relevant data into these smaller sandboxes, you’ll need to be able to filter and refine your test data, exclude attachments, and certain sets of data, all while maintaining integrity of the relationships for the data you’ve selected (see challenge #1).
3. Data Freshness
You’ve seeded your sandbox, but then new requirements are identified. In this situation, the development cycle often outpaces the ability to refresh the sandbox to get the latest copy of the metadata that fits those new requirements. The discrepancies here are often why your code may work in the Developer sandbox, but once it’s pushed into QA, it breaks.
4. Data Confidentiality
Because sandbox data is a subset of production data, it’s likely to contain confidential information that could be accessed by many people during development, testing, and training. Anonymization applied during the seeding process obfuscates data so that it is unreadable, replaced with mock data, or converted to an empty data set.
Protecting confidential data can be difficult. Providing unauthorized access to personal confidential information can be a huge liability for a company. It can happen easily when testing with real data. Are you currently anonymizing sensitive data before sending it over to your sandboxes? It’s definitely something you should be considering.
Anonymization is more than a good practice. Regulations such as GDPR and CCPA require companies to evaluate their technical and organizational controls to ensure compliance. Industry-specific standards and regulations such as the PCI DSS and the HIPAA also include strict privacy and security requirements.
Solve Seeding Challenges and Accelerate Digital Transformation
At this point, you may be trying to invent various DIY seeding tools that solve aspects of these four challenges using time-consuming, manual processes. From my experience, these DIY options are often like putting a bandaid on a cut that needs stitches. It may solve the problem temporarily, but in the end you’ll have to go see the doctor. Without an automated seeding solution from Salesforce AppExchange, it’s difficult to innovate quickly and identify coding errors before code is released. Before you head too far down that road, consider Enhanced Sandbox Seeding by OwnBackup.
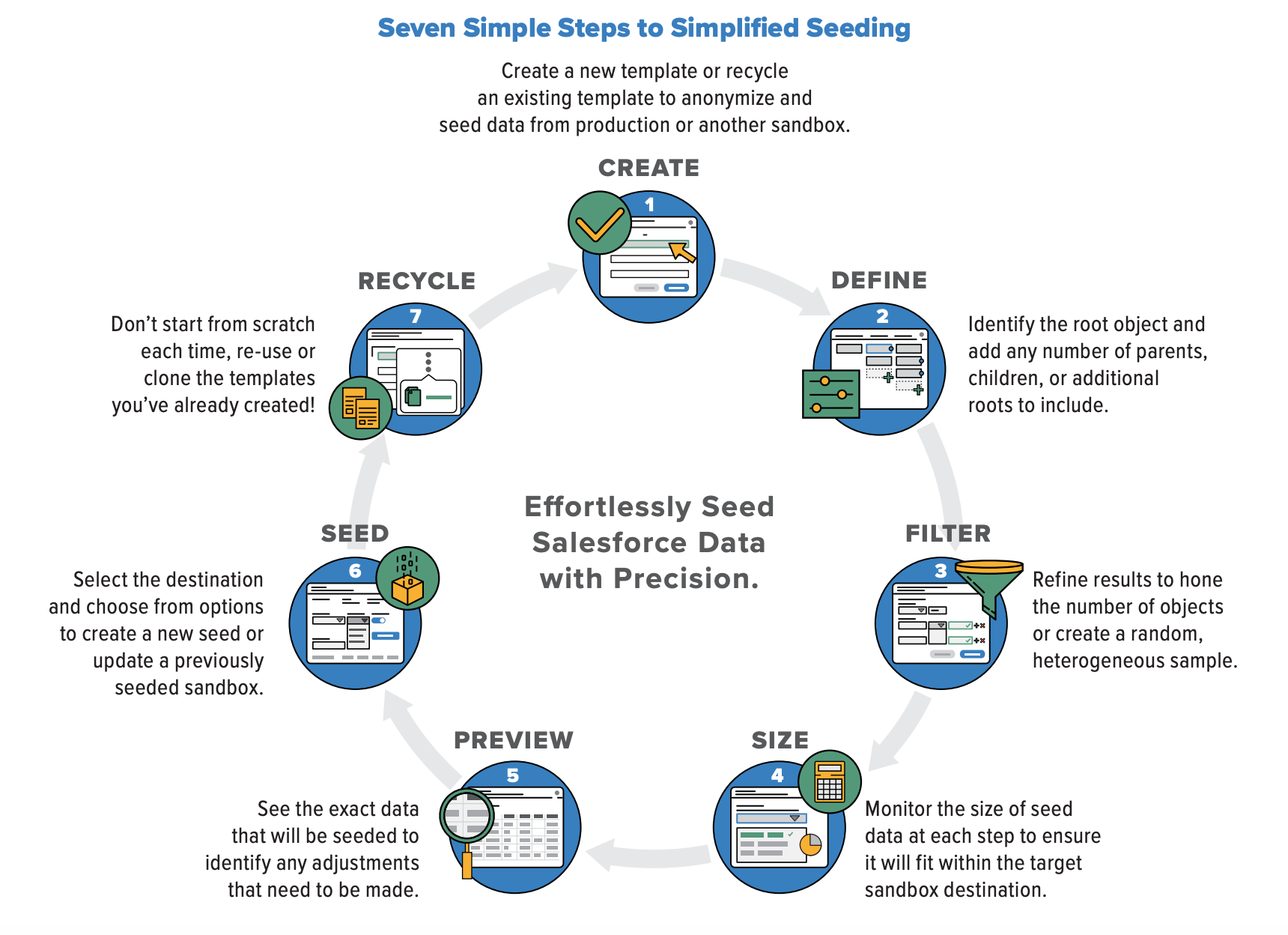
Enhanced Sandbox Seeding is an intuitive and powerful sandbox seeding solution for organizations that develop on the Salesforce platform. It enables developers and admins to effortlessly define, finetune, and automate the replication of precise subsets of data schemes from production environments or other sandboxes, then quickly seed them to Developer, Developer Pro, or Partial Sandboxes with identical metadata.




