





AI is evolving too fast for a “set it and forget it” strategy. According to recent SF Ben analysis, pledging loyalty to a single AI service is becoming a significant business risk.
With 75% of CEOs believing competitive advantage hinges on having the most advanced Gen AI, being tethered to a single model means risking obsolescence the moment a competitor launches a superior update.
Why You Can’t Rely on a Single-Model AI Strategy for Data Enrichment
1. AI Models Inherit Blind Spots From Training Data
An AI model is only as good as the data it’s trained on. As such, every LLM is limited by its knowledge cutoff, meaning it is functionally blind to any event that occurred after its training ended.
And because a model’s original learning process “hard-codes” these blind spots, you can’t just prompt these risks away:
- Invisible M&A activity: A model with a 2025 cutoff cannot accurately map account hierarchies for a massive merger that closed in 2026.
- Stale growth signals: Models without search capabilities miss real-time news signals like recent IPO filings, massive new product launches, and funding rounds.
- Stale data: Public companies report new revenue and employee counts every quarter, so relying on an LLM’s internal memory for this data risks outdated information.
2. Security and PII Compliance Force One-Size-Fits-All Workflows
RevOps teams work with a mix of public firmographics and personally identifiable information (PII), but treating them all the same creates unnecessary friction:
- Legal and data policies vary by model capability: Sticking to one model forces you to run every task through the most restricted environment, which strips away the advanced features that made the AI valuable in the first place.
- You have a limited choice of model size: If your data environment uses a high-reasoning model for PII safety, all data tasks become slow and expensive because it’s the only “authorized” tool.
Conversely, if your approved environment is built around an SLM for cost-efficiency, you won’t have the reasoning depth needed for efficient enrichment.
3. You Can’t Triangulate for Accuracy
Even for traditional enrichment, you don’t put all your hypothetical eggs in the basket of a single data provider because you understand their strength splits.
You likely use ZoomInfo for prospecting because it shines at contact data. But since it can be unreliable for defining child-parent relationships, you use D&B for corporate hierarchies because it offers the best breadth for identifying Global Ultimates and headquarters data – especially across EMEA.
The same holds true for AI models.
Without being able to triangulate data, you open up your AI data enrichment to multiple risks:
- Systemic logic bias. Every model weighs data differently based on its training. One might prioritize official legal filings while another focuses on recent web signals.
- Missing source verification. A multi-model approach lets you use a second model to check the work of the first, keeping your audit trail accurate.
Are AI Data Enrichment Platforms the Answer?
If the goal is to move away from a single-model dependency, the most common alternative is to use an all-in-one enrichment platform.
But before shifting your entire data strategy to an external provider, it’s important to understand the operational trade-offs and where these tools fit within your tech stack.
The Allure of a One-Stop-Shop
Specialized enrichment providers are great at building waterfalls – automated sequences that move through multiple data sources until a match is found.
- Integrated multisourcing: Some enrichment platforms can aggregate data from multiple providers simultaneously, pulling in firmographic data from traditional sources like D&B and ZoomInfo, as well as LinkedIn.
- Automated fallbacks: If one provider doesn’t have the data, the platform will automatically query another provider, and so on, until it finds a match.
- Agentic webscraping: As a final step, AI research agents can scrape the web for missing context and verify recency.
- Workflow integration: Most providers let you feed the enriched results into sales engagement or call-intelligence tools, making them useful for real-time SDR research.
The Friction of Credit Models and Operational Weight
Despite their power and convenience, these platforms do come with specific managerial requirements and costs.
- Specialized personnel requirements: Deploying these platforms typically requires a dedicated expert to “own” the tool, architect the logic, and manage the integrations.
- Setup time vs time-to-value: Because the system sits outside the CRM, you need to invest time to map fields and test the data hand-off between the platform and Salesforce.
- Credit-based pricing: Because of the added costs, teams typically use AI data enrichment platforms as a last resort and run primary enrichment through more affordable sources first to avoid blowing through their budget.
- Data quality conflicts: You risk the platform returning inferior data and overriding existing high-quality records.
Understanding Your Options for AI Data Enrichment
When you’re weighing a multi-model AI data enrichment strategy, you’re choosing between verified technical downsides and unverified performance upsides.
The choice typically falls into one of three paths, each with its own set of risks:
- Single-model: Sticking with one LLM to avoid complexity, which often leads to technical debt, thin data, and being locked in to a provider whose costs or performance could shift overnight.
- DIY multi-modal: Manually building an orchestration layer to swap models improves flexibility but adds operational pain.
- All-in-one enrichment platform: Using waterfalls to mix traditional providers with agentic scraping provides high-quality data, but forces your data and GTM rules into a black box outside of Salesforce. Also expensive.
These options all carry risk because most teams are forced to move straight from solution selection to execution without validation in between.
How to Safely Move From AI Selection to Execution
Moving safely from AI selection to execution comes down to three things:
- Seeing what enriched data actually does to your records before it goes live.
- Knowing which model performs best on your specific data.
- Having a repeatable process you can trust when you move to production.
It’s easy to skip straight to execution because there’s no obvious place to do the work in between.
A production environment is too risky to experiment in, and synthetic test data won’t surface the edge cases that actually matter.
What you need is a pre-production environment that lets you work with a real sample of your records, connect directly to the AI providers you’re evaluating, and keep your API keys and costs under your own control.
Complete Discover is one option built around this workflow, with tooling designed to help you identify the right task champions for your specific data needs before anything touches production. Here’s what that looks like:
Use Multiple Signals to Verify Accuracy
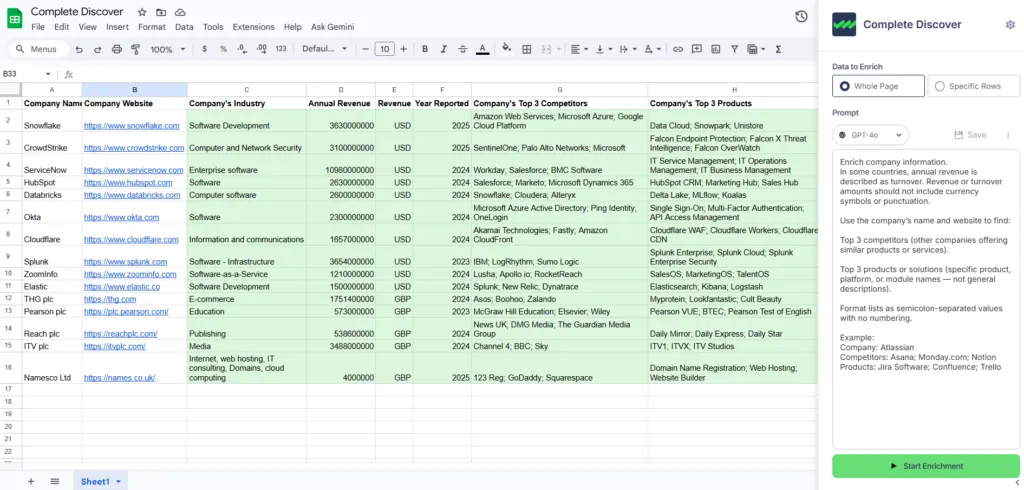
Running the same prompts across multiple models is the only way to verify AI-generated output, especially for events like Microsoft’s acquisition of Activision Blizzard, where different models can give conflicting answers based on their training data cutoffs.
Complete Discover is built for exactly this – run the same prompts across multiple LLMs to triangulate the correct answer.
Here’s what that looks like when enriching a complex account like Activision Blizzard to identify its ultimate parent company in a Salesforce account hierarchy.
- Column A (Data to enrich). Activision Blizzard
- Column B (Hierarchy identity). Who is the current ultimate parent company?
- Column C (Source verification). Find an official press release or SEC filing from late 2023 or 2024 confirming the status of the acquisition.
- Column D (Logic filter). Compare the results of Column A and B to the ‘Current Parent’ column in this sheet.
- Column E (Audit trail). Include the source URL(s) used to identify the match.
- Column F (Confidence score). Rate the certainty of the match on a scale of 1-10.
If the signals align, your confidence is high. If they conflict, a testing model is likely using outdated data.
This same multi-column strategy works for any complex data point where a single AI guess isn’t enough:
- Growth scoring: Calculate CAGR from financial reports to generate a momentum score and an audit trail of SEC filings.
- ICP qualification: Combine NAICS codes and product summaries for a logic-based “Match/No Match” verdict with a source URL.
- Regional territory mapping: Locate global HQs and regional hubs to automate territory routing with verified address URLs.
Benchmark Models and Identify Task Champions
Identifying the best model for your specific AI data enrichment needs requires pitting models against each other using real data.
In Complete Discover, you can run these “model bake-offs” side-by-side without any production risk:
- Run the first pass: Select a model (e.g., GPT-5.1) and populate a set of columns with your chosen prompts.
- Switch and compare: Open the configuration menu, swap to a different provider (e.g., Claude or Perplexity), and run the same prompts into a new set of columns.
- Evaluate the winner: Compare the outputs side-by-side. Look at the accuracy of the data, the quality of the reasoning, and the metadata like confidence scores and source URLs.
From Sandbox to Production
The prompts and workflows above are a starting point – the real value comes from graduating them into production.
If you want to see how Complete Discover and Complete AI work end-to-end, here are two resources worth bookmarking:
- See the Complete Discover in action. Our on-demand Complete Discover demo shows how to safely validate data, experiment with account enrichment, and augment hierarchies in a spreadsheet before risking your Salesforce environment.
- Build your AI-powered RevOps engine. Our guide on How to Build the AI-powered RevOps Engine covers how to graduate these prompts into production, implement workflows that scrape real-time M&A signals, and build an automated multi-modal AI enrichment waterfall.




