

In “Salesforce DevOps: Learnings from 300+ Salesforce Deployments” I detailed my experience of using DevOps with Salesforce to deliver successful projects. We covered typical implementation models, as well as how to choose the right deployment mechanisms and the importance of version control. In this article, we’ll dive even deeper into lessons learned during my journey to build a DevOps pipeline.
What is a DevOps Pipeline?
A DevOps pipeline is a set of practices, processes and tools that teams (Development and Operations) use to build, test and deploy software. A DevOps pipeline ensures that software development is organized efficiently and thoroughly tested to avoid costly errors.
My DevOps Journey
So, how did creating a DevOps pipeline become such an important part of my role, and why might you need one too?
My team and I were working on a project with an extremely tight and fixed deadline. The team was also working across locations and time zones so communication and working together was going to be critical to our success. We realized that our traditional deployment process of using Change Sets or ANT was not going to help us meet our strict deadlines. We decided we needed to build a DevOps pipeline that we could use in our day-to-day deployments.
A DevOps pipeline would help us to:
- Merge code in a central repository
- Set up configuration and infrastructure management
- Implement version control
- Automate tests
- Monitor and control deployments from mobile device
- Ensure code quality
- Enable easy communication with the team
Tools Used During Our DevOps Implementation
1. Version Control System (VCS)
Version Control keeps track of the changes made to the code; if there are any issues, version control helps us to compare the code base with the previous version, then locate and fix the issue. We used “Git” as our VCS since our customer had their other projects on Git.
2. Branching Strategy
A branching strategy is a convention, or a set of rules, that describes when branches are created, naming guidelines for branches, what use branches should have, and so on.
This was the toughest part in our DevOps implementation and I would like to highlight a few advantages of a good branching strategy:
- Reverting changes becomes easier
- Code override issues will be significantly reduced, and in case of issues, we can revert changes easily
- Helps to deploy any change independent of other changes
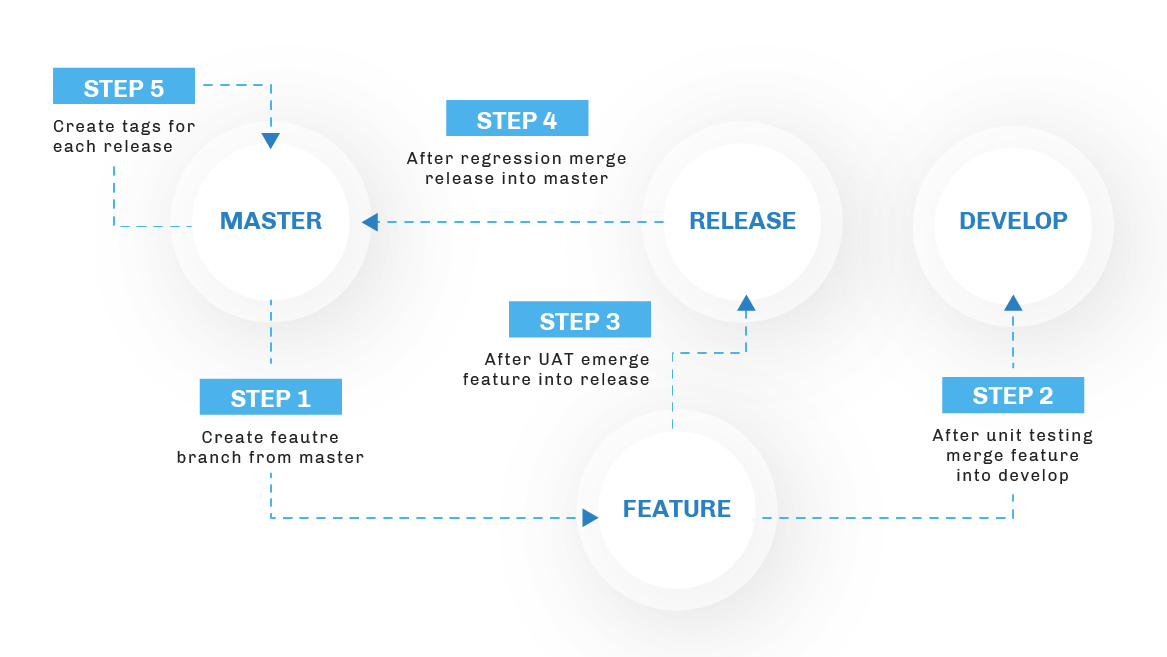
We followed a feature-based branching strategy which was the outcome of our discussion with the team. In this branching strategy, we had the following branches:
- Feature – for every feature / JIRA ticket, developers create a new branch from master
- Develop – active branch where we merge our day-to-day changes
- Release – before moving our changes to production, we first merge them in release
- Master – replica of what we have in production
Branching Strategy flow:
3. Sandbox / Org Arrangement
Salesforce provides various types of environments to do development, testing, bug fixing and so on, which are called sandboxes. Every Salesforce customer, based on the implementation complexity, uses sandboxes differently. It can be as simple as a single sandbox that is used to do development and testing and it can be complex with multiple orgs used. In our development lifecycle we have 5 different environments wherein each has its own purpose. These are explained below:
| Org name | Purpose |
|---|---|
| DEV | Developers will use it to do development. This ideally should be a scratch org and not a sandbox. |
| UNITTEST | After developer merges his code in Develop, changes get deployed to this sandbox where a developer will unit test his changes. |
| QA / SIT / UAT | Used by the Quality Assurance team to do the testing. |
| PREPROD | Before production, release changes are deployed and tested here. Ideally, this org is a full copy sandbox. Very useful in reproducing production issues to provide a fix. |
| PROD | Live org. |
Pipeline Flow
In our first round of iteration, we implemented DevOps as shown in the diagram below:
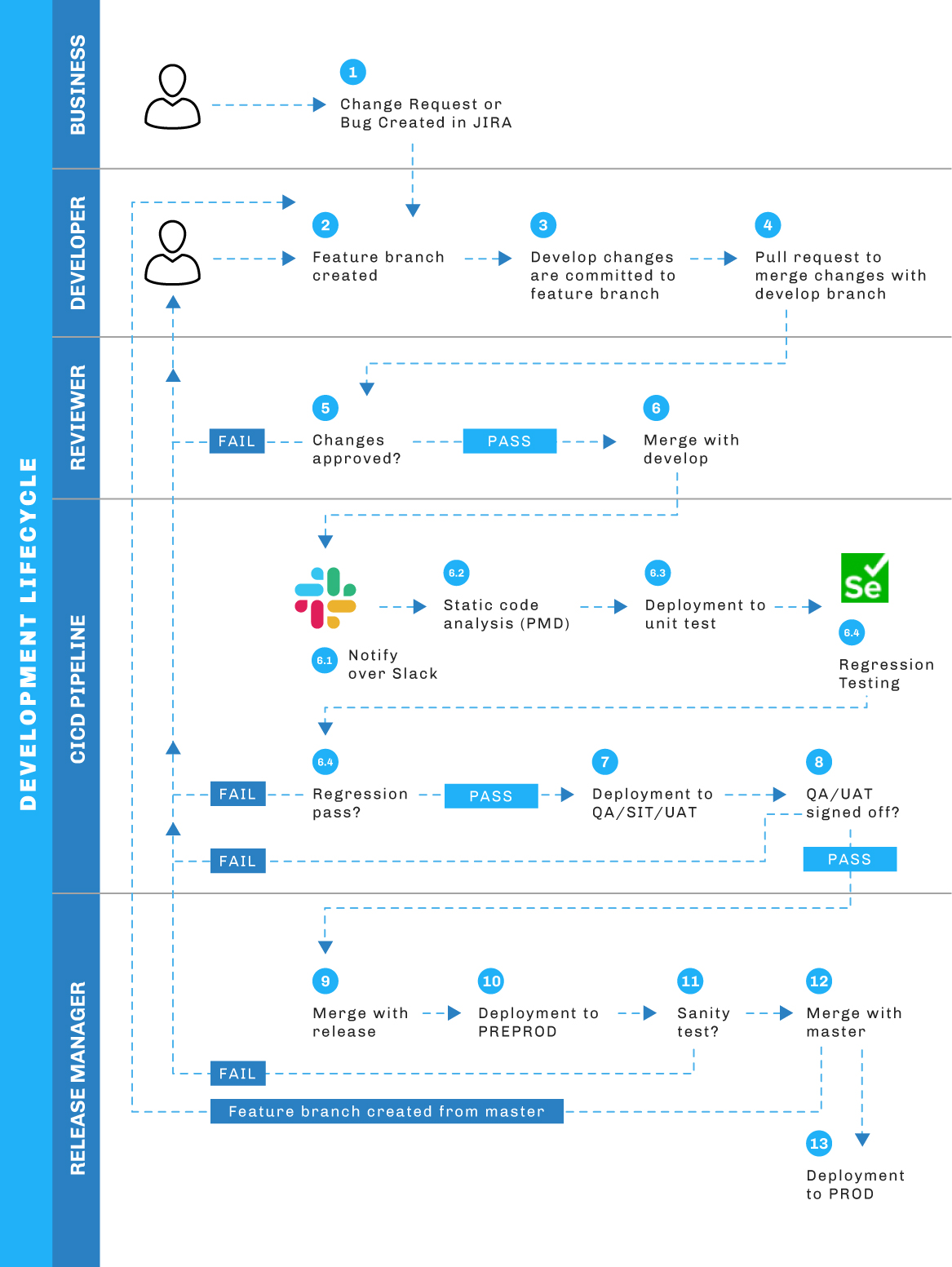
- Change Request (CR) or bug created.
- Developer creates a feature branch from expert for that CR or bug by using the ticket number.
- Developer commits his changes to the feature branch.
- Developer creates pull request from his feature. Branch to develop branch and assigns the reviewer.
- Reviewer will do the following:
- a. Code Review
- b. Request Changes
- c. Merge changes in develop branch
- Once the changes are merged, DevOps pipeline will be triggered, and it will start deploying changes to UNITTEST org.
- a. Notification on various channels to inform relevant people that deployment is triggered (in our case we sent notification on Slack).
- b. Integration with static code analysis tool – obvious things which might go wrong can be tracked by using this tool. This will also help in having good code quality.
- c. Deploying changes to UNITTEST org.
- d. Integration with automation test suites – automated test cases are executed to find if there are any regression issues.
- After that, the developer will do unit testing in UNITTEST org.
- If there are no issues, deployment will be approved for QA / SIT / UAT sandbox, else the developer will fix any issues and again merge his changes in develop branch.
- After the change request is tested and signed off by QA / Business team, features are merged with the release branch.
- All the steps mentioned from 6.a to 6.d will be executed and deployment to preprod will be done.
- Sanity test will be done in PREPROD. The release manager will initiate an approval request if there are no issues during sanity testing.
- Release manager will merge changes to the master branch which will trigger the pipeline for production.
- Deployment to production.
TIP – If it is only about deploying changes then what is the advantage of DevOps? That might be the question you have on your mind.
So, to answer that: the DevOps pipeline will not only do deployment; it can be configured to do a lot of things that are particularly important in SDLC:
After we implemented our first pipeline which helped us doing seamless deployments, it was time to enhance it to reduce some challenges that developers might face during deployment.
Our DevOps Pipeline Features
As explained above, based on our learnings we built a DevOps pipeline for Salesforce deployments. We then added some key features in our pipeline, outlined below, which helped us a lot during deployments.
Full Deployment
Full deployment is deploying all the components in a branch to the Salesforce instance. Below are some key characteristics of full deployment job:
- Used only for sandboxes.
- Nightly jobs are executed.
- Ensure that all sandboxes are coordinated with develop branch by overriding the direct changes made by any developer or admin in QA / UAT sandbox.
- Run all test classes – this helps to keep a check of our test classes. There are chances that test classes might fail because of recent changes introduced. Complex orgs take a lot of time to execute test classes which cannot be done in working hours. So, this will notify developer and he can take necessary action.
Incremental Deployment
Incremental deployment is deploying only those components which are modified since the last successful commit was made to the target branch:
- Used for sandboxes as well as production.
- Used for all day-to-day deployments.
- Deployments are faster as less components are needed to be deployed.
- This feature is about picking only those components from our branch which were modified since our last successful deployment. When a developer commits his changes in feature, the developer does not have to provide manifest file (package.xml). Our workflow automatically picks up the components and deploys them.
Why is this helpful? The Developer maintains a manifest file (package.xml) to maintain a list of his changes. When there is a need to do deployments from one org to another, those can then be used. With this feature, one need not worry about maintaining a manifest file for deploying changes in different orgs. Manifest files will only be required to commit his changes in feature branches. The DevOps pipeline will take care of the rest.
Test Class Management
Salesforce deployments require successful execution of test classes and code coverage should be more than 75%. Salesforce gives us 4 options for running test classes while deploying our changes:
- Default
- Run local tests
- Run all tests
- Run specific tests
There are few questions that arise in developers’ minds about test classes:
- Whether executing test classes is required or not?
- Which testing option out of the 4 options should be chosen for deployment?
- Which test classes to run?
Below are some considerations when running test classes.
1. Run Specific Test Classes
While doing deployments using change sets or ANT if the developer uses “Run Specific Tests” option then the developer has to maintain a list of test classes that need to be executed to proceed with deployment. Our pipeline is smart enough to find which test classes to run. This reduced developers’ workload of maintaining a list of test classes to be executed. Developers will have to do one-time mapping of apex class and test class in a json file. And then our pipeline will do the rest of the job for the developer.
2. When To Run Test Classes
When deploying our changes, if we specify test level as “Default” then Salesforce decides whether to run test classes or not, based on what is getting deployed. This is good if we are deploying layouts, email templates, flexi pages, etc. but if we are deploying validation rules or Flows which might break our system, it does not run test classes which I feel it should do.
We now maintain a set of component types for which the system should mandatorily run test classes. This set of component types can be modified based on our requirements. This will help us to avoid regression issues in the system which might be introduced by marking a field mandatory, adding a validation rule, unhandled exceptions in Flow on a core object, etc.
3. Mandatory Test Classes
Unfortunately, it’s not uncommon for there to be changes in personnel during a project, and it’s impossible for a developer to be aware of all the touchpoints about the system. Having documentation will help the developer in understanding everything just by reading. In order to do regression/sanity checks, we maintained a set of test classes that should run for each deployment only if test class execution is required based on a previous feature. These test classes will make sure that changes do not impact the core of our system.
We have now added a feature in our DevOps pipeline which will find the list of test classes to run for this deployment. We also maintain a json file that has a mapping of a class and its test class which is used by our workflow to find test classes. You can provide multiple test classes for one class.
Summary
This is not the end! We are still enhancing our DevOps pipeline to add more benefits. A few examples of exciting plans, currently still WIP, include:
- Generating release notes – we can get a list of components which are modified in this deployment in a document.
- Code documentation – we did a PoC for this. This is possible: we need to follow certain formats when we add comments in our code.
- Static code analysis – we are using it to do analysis but not for taking any actions. We will try to use this tool more to enforce some rules which will improve code quality.
We have been working on this over the past year, during which time, we faced a lot of issues and certainly made some mistakes along the way! However, we are now proud to have our DevOps pipeline ready to go and continue to feel a lot of enthusiasm about our plans for future enhancement.

Comments: