

Duplicate management is a critical task to keep Salesforce data clean, consistent, and complete. However, many admins stop at the basics and miss more effective dedupe opportunities. Or they accidentally over-merge records due to flawed match rules.
Enter data profiling, the often-overlooked superpower of Salesforce admins. Data profiling can significantly enhance your data matching algorithm use and data quality controls in two ways. Firstly, it identifies all possible fields for duplicate management. Secondly, it determines potentially problematic data content upfront so you can address issues.
In this article, I will share four ways to use data profiling to take your duplicate management strategy to the next level.
1. Determine Fields for Matching
Duplicate management starts by identifying the fields to use in the matching rules. Data profiling is pivotal, providing insights into field usage and reliability.
Account, Contact, and Lead records contain multiple fields that you can use in your matching rules, yet some will be more useful for matching than others. Data profiling shows which fields are consistently populated, guiding admins to choose the most reliable fields for matching criteria.
Let’s take a look at phone number fields as an example:
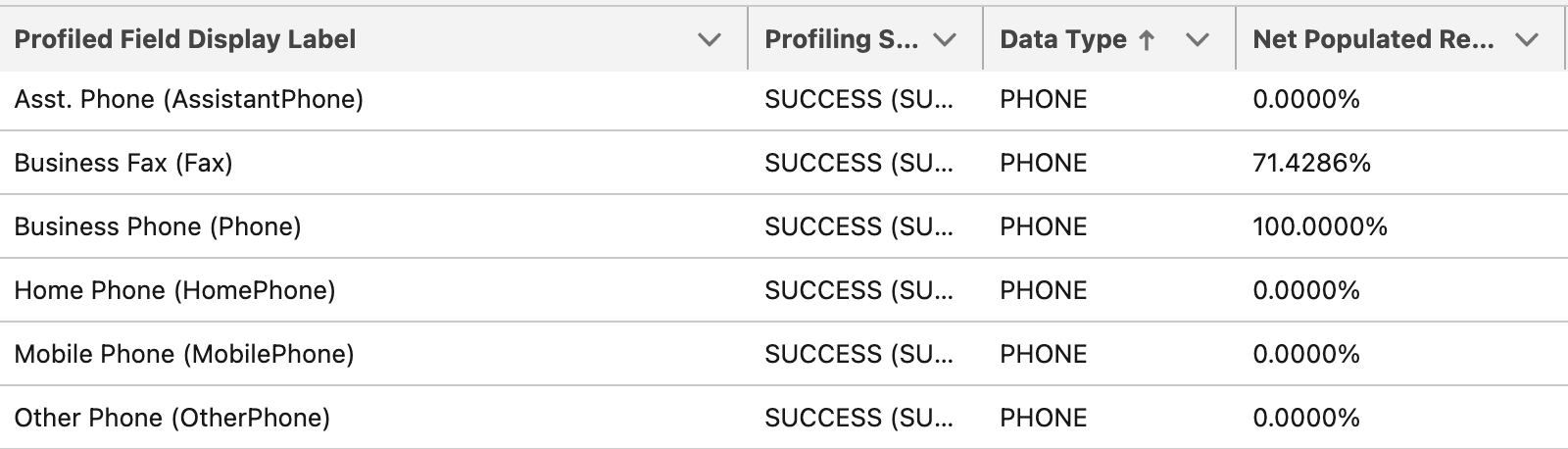
In the age of mobile devices, are you surprised to see a high fill rate for the Fax Number field? Fax machines are still one of the most prevalent forms of communication for transmitting care records and prescriptions. Healthcare organizations can have multiple phone numbers, but typically they only have one fax number. Adding this one additional field to your match rules could be key to your duplicate management outcomes.
Identify all potential fields suitable for matching to achieve optimal results. In addition to the obvious name and contact point fields (email, phone, URL), evaluate external IDs and string fields based on uniqueness. Fields with 100% distinct values are completely unique, meaning no value appears twice. However, you may be able to use fields with 75% distinct values or higher as unique identifiers. Unless working with transactional data, currency, and date fields are rarely relevant in duplicate management.
Combining fields may yield additional unique values for matching purposes. The most simple example of this is combining address fields.

2. Address Bad Data Before Matching
Once you have identified potential fields for matching, the next step is to assess their quality. How often do inaccurate and fake values appear? Are users populating fields with real, but invalid data to bypass validation rules (e.g. using their email address when the customer’s is unknown?) Data profiling highlights data quality issues that could skew matching results.
Data profiling can pinpoint bad data for cleanup and even provide clues about its origin. Profiling results highlight when data content deviates from expected standards (e.g. unexpected field lengths).
Disproportionate value frequency can also signal invalid data that will mess up your duplicate matching. Identify fake data by looking at field values that occur too often in your match fields (e.g. noemail@noemail.com, John Doe).
Catching data quality problems early is key! Clean your data by fixing mistakes and removing bad entries before they mess up your duplicate matching.
3. Configure More Effective Match Rules
With a clear understanding of which fields are reliable and clean, admins can configure precise match rules. Data profiling helps you create better matching rules, revealing patterns and common ways data is entered in Salesforce. This lets you create accurate rules that catch duplicates, even when people enter information in slightly different ways.
4. Evaluate Results for Merging vs. Linking
After implementing match rules, it’s time to evaluate the results and decide whether to merge or link duplicate records. Data profiling shows the quality and context of matched records flagged as duplicates. This information helps admins decide whether to merge duplicates, link them as related records, or even leave them separate if they’re actually distinct entries.
Best Practices for Using Data Profiling in Field Selection and Cleanup
Data profiling’s analysis provides invaluable insights for effective duplicate management. Understanding field fill rates and the distribution of field values helps determine which fields to use in matching rules. Data profiling also pinpoints fields that likely need cleaning before they’re useful for duplicate management.
Follow these best practices to ensure the most effective duplicate management rules:
- Evaluate all Email, Phone, and URL fields for possible inclusion in your matching rules.
- Assess the fill rates and uniqueness of common contact point fields to determine their usefulness in matching. Also, assess fields classified as PII.
- Identify fields with high levels of uniqueness to use in match rules.
- Explore using formulas to concatenate fields to generate a unique identifier.
- Delete known invalid values when you can. If unsure, create a temporary field as a backup and only use the field with cleansed values in your match rules.
- Use additional identifiers when possible. E.g. TrailBlazer ID for an individual (vs. business contact), DUNS number for accounts, etc.
- Assess the field value frequency of your match fields to identify fake values and remove them before matching.
How Duplicate Matching Works
Matching involves creating indexes based on selected fields, which serve as the basis for comparing records. To improve matching accuracy, you can compare information from different fields within one record. For example, the same phone number may appear in the Phone field in one record and in the Mobile field in another.
The integrity of these matching indexes is crucial, as they directly influence the outcomes of the matching process. Data profiling ensures the data fed into the indexes is reliable. This, in turn, leads to more effective matching and management actions like merging or deleting duplicate records.
Final Thoughts
Tired of duplicate records cluttering your Salesforce CRM? Data profiling isn’t just an extra step – it’s your secret weapon for better deduplication. Uncover hidden patterns and inconsistencies to create smarter matching rules and achieve cleaner data.
Ready to build a smarter, more efficient duplicate management strategy? There are plenty of native data profiling solutions available on the Salesforce AppExchange.
