SalesforceSummaries: a series delivering key insights from Salesforce YouTube videos, to save you time as you keep up to date with the latest technological changes within the Salesforce ecosystem.
Introduction:
Because the rate of data growth is so fast, it is becoming increasingly critical for companies to be able query on data quickly. Big data is no longer sufficient — fast data is a new term that has been coined to encapsulate the new paradigm.
Salesforce have experienced huge data growth among their customers and they continue to invest heavily in providing new tools that facilitate performant queries. This summary highlights the key tools that Salesforce provide as well as important strategies that can be adopted to prevent a ‘big data blowout’.
Details: ‘Tools and Techniques for Managing Big Data in Your Org’
Presenter: Moyez Thanawalla
Time: 40 minutes
Key Terms: Performant queries, big data, fast data, aggregation
1.@0.10 — A ‘big-data’ blowout on your Salesforce database is very possible. One client couldn’t run their database, couldn’t run list views or queries.
2.@0.55 — There are some key strategies and tools which can be leveraged to ensure a performant database.
3.@2.30 — Last year, typically, clients would have ~ 5 million records in their respective Salesforce databases. However, nowadays, it’s not unusual to see clients with more than 50 million records and many, many clients have ~ 10 million records. This huge data volume growth can be a huge technical challenge. The growth rate (a factor of 10) shows no signs of stopping and in fact, it is speeding up.
4.@3.20 — Earlier this year, Entrepreneur magazine published an article about why ‘big data’ is not enough — it has to be ‘fast data’. This article hypothesised that the key challenge that IT teams will face is not storage, but rather to make the data performant. If we don’t address this problem now, then this represents a huge ‘threat’ to IT teams.

5.@4.40 — An analogy to present the issue effectively is that when IT run a query, they are looking for a needle in a haystack. And the haystacks keep getting bigger and bigger because there is a clear business value in storing more data: ‘we need to know more things about more transactions about more customer touchpoints’. So the haystacks are getting bigger and the needles are getting smaller. That analogy represents the calibre of the pain that some IT teams will face over the next few years, unless the issue gets addressed.
6.@5.30 — This challenge isn’t hyperbole. A real use case is discussed. The below chart represents the data growth volume of a customer.
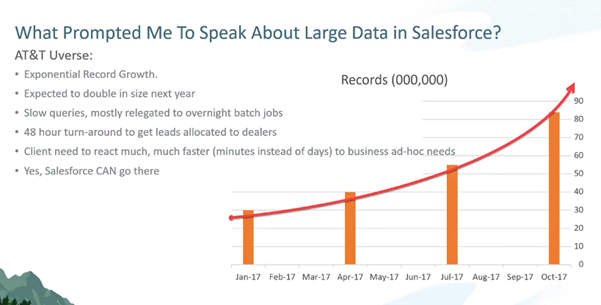
7.@5.45 — The pain was really felt around April (~ 40 million records) as slow queries were common.
8.@7.05 — Ray Kurzweil, author of ‘The Singularity is Near’, discusses how the global data growth value is growing at an exponential rate even on a logarithmic scale.

For context, as per this link, the following analogy is helpful to help represent how vast a zettabyte is:

9.@8.45 — Salesforce have scaled their own processing capabilities to meet the current and forecasted data growth. The Salesforce platform sits on top of an Oracle engine and this presentation will cover optimization strategies to apply on Salesforce queries, since the underlying Oracle SQL database cannot be optimized by customers.
Salesforce are dealing with customers who quite easily have more than 10 million records now.

10.@10.30 — There are a number of steps to Salesforce database success:

11.@13.20 — You are not controlling the query that Salesforce executes. Rather, you are writing a ‘metadata’ as you will, which is interpreted by the Salesforce engine; which goes through an optimization process and executing it on the underlying database.

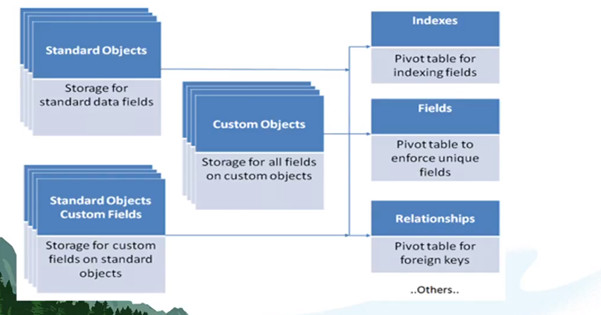
12.@15.00 — When a query on both standard and custom fields is run on the Account sObject, for example, it appears that Salesforce is returning the result having searched a single data table. However, Salesforce split up data from an object into many different tables.
Object and table are commonly used synonymously however, strictly speaking, an object is a virtualisation of the underlying tables. So when you run a query on the Account object, the query actually runs across a number of different tables. This approach is very different to a SQL query.
13.@20.00 — Many companies use UML diagrams across the board. However, as useful as UML diagrams are for many use cases, a UML diagram obfuscates the relationship amongst different tables in a data schema. Look at the schema diagram tool in Salesforce to visually show the relationship between different tables and the relationship between them.
14.@21.00 — Indices in Salesforce are slightly different to what you might have worked with in SQL. There are certain fields that are automatically indexed without having to do anything. The set of fields in the left hand column are automatically indexed on the majority of sObjects (Salesforce objects).

15.@22.30 — Salesforce also supports custom indexes on custom fields. You can open a ticket with Salesforce (provide Org id and the API field name) and request an index on a custom field — as long as it’s not a data type that is in the second column.
16.@24.00 — Creating indexes is an important part of database design because indexes don’t do full table scans and so are faster. A query which contains an indexed field in the WHERE clause will result in the index table being queried instead of a running a full table scan on another table.
17.@26.00 — If a standard query takes 10 milliseconds instead of an optimized indexed 1 millisecond query, then if your data set is below a certain threshold, the 10 fold increase is negligible — you won’t really notice it. However, as your data set volume increases in your Salesforce org, this is when the optimized indexed query really starts to pay dividends.
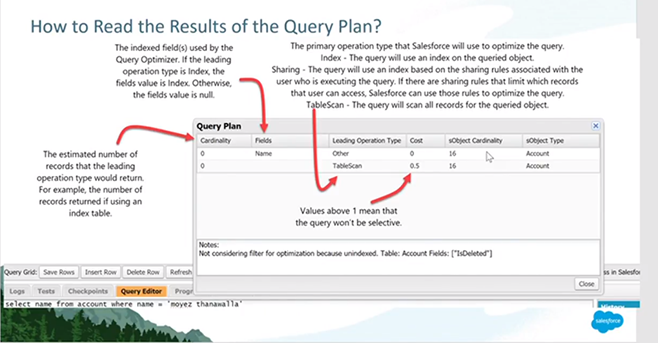
18.@27.00 — The Salesforce force.com query plan tool can be turned on in the Developer Console. The query plan tool gives you the different options that Salesforce is considering on the query that you want to run. Under the covers, whenever you want to run a query, Salesforce runs the query tool to determine the most performant way of querying the database, and then it uses that path. So by using the query plan tool, you can see if there’s any options for you to optimize the query.

19.@28.30 — At all costs, you will want to avoid a full table scan.

20.@29.10 — To turn the query plan tool on, go to the Developer Console and then navigate to Help | Settings | Enable Query Plan Tool:
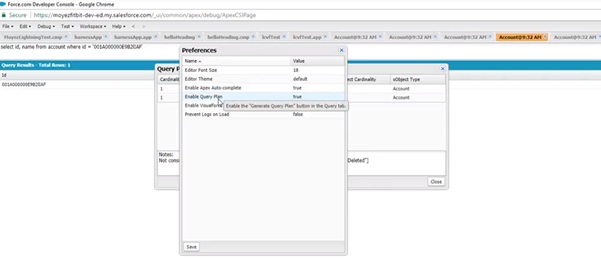
21.@29.30 — Once the tool is enabled, you’ll notice the ‘Query Plan’ option at the bottom of the page on the Developer Console.
22.@30.10 — Once you input a query and select ‘Query Plan’, you’ll see the different options that Salesforce is considering on the query:
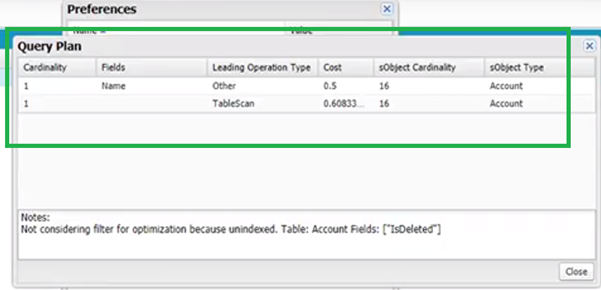
This Salesforce document covers the Query Plan tool in more detail.
23.@33.00 — When you select a negative query (such as WHERE fieldA != ‘value’), these types of queries will ‘eat your lunch’ — they are very costly from a database scan perspective. The cost will typically be far over 1.0. You want to keep your queries below a cost of 1.0. You should avoid using negative query selectors where possible.
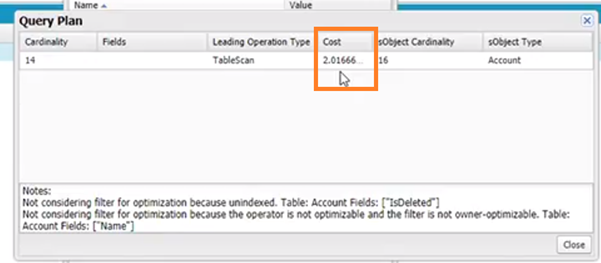
24.@35.00 — @35.00 — Indexing is your friend as this will result in selective queries that have a far lower cost. For example, the SOQL *select id, name from account where id = ‘001xxxxxxxxxxxx’ *has a very low cost.

25.@36.00 — The query plan is the best tool that you have as your data set volume starts to grow.
26.@37.00 — In one example, a customer had 84 million leads. The leads fell into different buckets, which could be abstracted away. For example, income level, car that the lead drove etc. So if one wanted to find the results of all households in a certain neighbourhood with an income over a certain value, then that query could be executed on a custom object which stores the aggregated data instead of the lead object itself.
By aggregating the data, the 84 million records went down to 400,000 records (less than 5% of what the original, un-aggregated data set is). It’s beneficial to aggregate large data sets into a custom object, which can then be queried on to be far more performant.
‘How can I abstract data away into a custom object?’ — is a database design phase question.

