

This year’s Dreamforce left our heads spinning with the possibilities of AI. If you believe the actual Gartner® Hype Cycle® on AI, we have reached peak generative AI hype. If that’s the case, what happens next is anyone’s guess; we can’t know the future.
Still, there is a consensus among technologists, journalists, policymakers, and academics that we’re at the beginning of a major shift in technology.
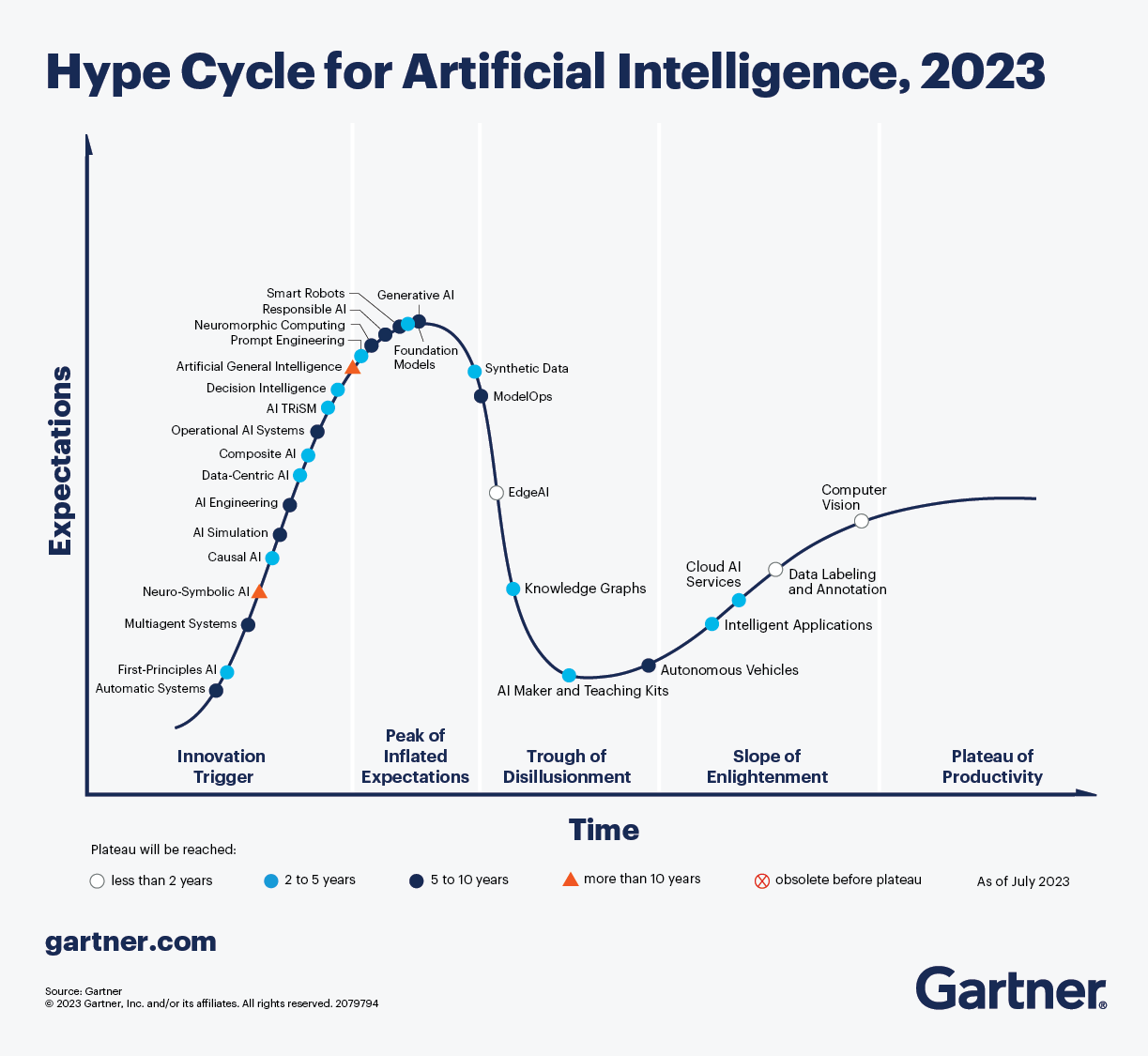
The graph below shows Gartner’s take on the artificial intelligence hype cycle, which “identifies innovations and techniques that offer significant and even transformational benefits while also addressing the limitations and risks of fallible systems”.
My Story
Generative AI excites me, especially large language models (LLMs). Because my career has always been about communication, writing, and content, I have a huge affinity for this form of machine learning (ML).
Because of this, I made the choice earlier this year that I was going to work my way into this branch of technology. I should probably write another article about how I’m doing that, come to think of it.
Joining the groundswell of a technology during the rise of inflated expectations can be risky. But the scarcity of expertise creates opportunities for those dedicated to learning that technology. And if the technology really takes off, you are placing yourself in the position of becoming an early expert, which can have huge rewards later.
So, if the possibilities of AI and ML have you excited or maybe just curious enough to want to learn more, where do you start? As someone like me, who was a complete beginner to AI (apart from just knowing some basics) how can you get on the bandwagon?
These are opinionated pieces, so I’m not attempting to create a comprehensive list of anything. Rather I will focus on 12 key aspects of the AI world that have helped me begin to wrap my head around the current state of AI, its past, and possible future. These are things I have encountered as I try to find where I want to fit into this part of technology.
Transformers
The transformer is the architectural basis for all the Generative AI excitement that we’re all feeling at the moment and is responsible for the “T” in GPT. It arrived on the scene through a research paper in 2017 often called The Transformer Paper.
It sent shockwaves in the AI world at the time. It was published as a major innovation in text translation, but soon people learned it could be applied successfully to several other natural language processing (NLP) tasks. Researchers soon discovered transformers even worked well with unstructured non-text data like images and video.

The innovations introduced by transformers were simplified architecture compared to previous NLP architectures, parallel processing of text, and the ability to scale the model on larger amounts of data. The paper’s actual name is Attention is all you need. So what is attention?
Attention
Attention is the distinguishing feature that makes a transformer a transformer. It was not a new invention. However, the team behind the transformer paper took the attention mechanism and applied it to natural language AI in a new way. By focusing their solution on the attention mechanism, the team came up with an architecture that was a lot simpler than what had previously been the state of the art.
As you can see from the transformer architecture diagram, although simplified, the transformer is a complex piece of technology. One of the best simplified but still technical takes on this is Jay Alamar’s The Illustrated Transformer, which can also help clarify how the attention mechanism works. You still need some basis of machine learning knowledge to get all of it, but it is easier than the transformer paper!
Model
A model is a set of mathematical functions combined with a set of statistical weights that have been derived from a known data set. Once the model has those weights you can provide some new data (an input) and make a prediction (the output) based on patterns the model has learned from previously known data. The process of deriving those weights is called training, which I further describe later on.
The job of the machine learning engineer is to select the right machine learning algorithm for the type of data at hand. This is important to remember at this time of high LLM hype. There are lots of other models out there that might be better suited to some tasks than an LLM.
A successful model is often said to generalize well. This means that when you feed it new data values, it can make accurate predictions. This is a good way to think about LLMs. When you provide an LLM with some text, it uses the weights it has been trained on along with the transformer architecture to predict the next word.
Embedding
Since machine learning is essentially complex math, one of the problems with using it with words is creating effective numeric representations of language. Embeddings take words, partial words (tokens), and sentences and identify how contextually similar one word, token or sentence is to any other word, token, or sentence in the embedding.
Before text is passed to a transformer in an LLM, each word is passed through an embedding algorithm based on that model’s training data set. It’s these number values that the transformer uses to eventually derive its predictions. Nomic.ai has a super cool tool called Atlas to create a visual map of model embeddings, including some live examples!

Parameters
The term parameter refers to the probabilities (sometimes called weights) that a model has determined based on the training data. Referring back to the model definition, your model (a set of maths operations and a set of parameters) is what you feed your input data into (text, in the case of an LLM) which then outputs a prediction or an output.
Tokens
Words or partial words. Generally, documentation will define them as being 3-4 characters, but each LLM has its own way of turning words into tokens (called a tokenizer). LLM’s use tokens to measure how much input they’ll accept, how much output they can produce, and the size of the data they were trained on. While not the output from an actual tokenizer, below you can see how the words “Forward looking statement” might be converted into tokens.
Forward looking statement
For ward look ing st ate ment
Training
For ML models to work they require data. In LLMs, this is done first by feeding large amounts of text into the model in a process called pre-training. Models are then often fine-tuned, a second step of training that allows you to take a basic model and further refine how it works. Fine-tuning can make models more specific around a certain domain of knowledge, a purpose like a chatbot, or a type of language like a programming language.
LLMs tend to be identified by the number of tokens used in pre-training and their purpose. For instance, the Llama-2-7b model is the Llama version 2 model that was trained on 7 billion tokens. The Llama-2-7b-chat model is the same dataset but fine-tuned for dialogs and chat.
When coming up with the total cost of using an LLM, training the model is a one-time cost. For the largest LLMs, the training costs have been reported to be in the tens of millions of dollars, but there are examples of good LLM models that cost a fraction of that.
Inference
The moment in time you pass a new input to an ML model and it comes up with an output or prediction is called “inference time”. When coming up with the total cost of a LLM, inference cost is an ongoing expense that is not trivial. A recent report in the Wall Street Journal claims Microsoft is losing $20 per user per month on GitHub copilot.
The potentially high training and inference costs of an LLM are one of the main reasons why a company might select a more task-specific ML model over an LLM.
Hyperparameter
Whilst parameters are learned by the model during training time, hyperparameters are the ways that the human using the model can change how the model behaves. A key LLM hyperparameter is temperature.
Proper use of hyperparameters can help in getting an LLM to generate the text you want. The more you understand how each one impacts the model output, the more likely you are to get the model to work well for you.

Temperature
A hyperparameter to control how “creative” or random a model can be when it is inferring an output. The model uses it to determine how strictly it follows the probabilities of the output predictions. A lower temperature means more strictly following the probabilities. A higher temperature introduces more uncertainty, and thus more creativity. Too high a temperature turns the predictions into a total mess.
If you’re using a model to understand and summarize important factual data, you’d want to use a low temperature, maybe even zero. If you’re a creative writer and using a model to brainstorm a new story plot, then you would want to use a higher temperature.
Below are three example generations from the GPT 3.5 Turbo model made through the Open AI playground. The GPT models use a temperature range of 0-2. The temperature values of 0 and 1 show a more plain and more creative generation. The generation with temperature of 2 is unusable.



Agent
Think of an agent as an app or a service built on top of AI models. Although strictly speaking according to how the term is used, both humans and robots are considered AI agents when they interact with them. Agents often use multiple AI models to accomplish a specific goal. For instance, a voice-to-image agent might use a speech-to-text model (like Whisper) to generate text spoken from a user and then pass the text to Dall-e, a text-to-image model.
We’re all already using AI agents all the time these days. That little widget that predicts the next word while you tap on your phone? That’s an AI agent.
Making multiple model invocations can be complex. For this reason, there are whole frameworks that have been created to make this more simple, such as Langchain. There are all manner of no-code AI agent start-ups as well. If I have a prediction to make in the Salesforce space it’s that they either create a set of flow components to construct AI agents, or that a few partners pop up in the vein of Vlocity that do this.
Confidential Computing
Although it is not strictly AI-related, confidential computing seeks to secure data while in use. As opposed to at rest or in flight. Previously confidential computing was focused on CPUs. It has now been introduced into GPUs. This is likely to enable more secure AI processing in data centers that share a GPU between many clients to prevent data leaking between them (either accidentally or by malicious means).
If Salesforce aren’t already using confidential computing in their use of AI, I would expect they’re actively investigating options along this line
Summary
With any new technology that you learn, there are plenty of new terms to get your head around. While this list is definitely partial, and some of them may not have sunk in just yet, just knowing that you may run into these things should help you be prepared as you wade into the discourse around AI.
